

Passer de la théorie à la pratique avec l'IA
7 jours au lieu de 90 : ce qu'on a mesuré en développant un outil réel

Depuis un an, tout le monde vend de l’IA. Des promesses de gains x10, des démos sur des cas fictifs, des keynotes qui montrent ce que l’IA “pourrait” faire.
Chez Hones, on accompagne des dirigeants tech au quotidien. On ne pouvait pas se contenter de leur dire “faites de l’IA” sans l’avoir éprouvé nous-mêmes, sur un vrai cas métier, avec de vraies contraintes.
Alors on a pris notre propre activité comme terrain d’expérimentation. On a décidé de développer un outil d’audit tech augmenté par l’IA. Dashboard de mission, notes d’analyse classées par thématique et criticité, génération de rapport avec revue collaborative.
Pas pour déléguer notre métier à la machine. Mais pour gagner du temps sur tout ce qu’il y avait autour : de la connaissance dispersée, du copier-coller, de la mise en forme. Du temps passé sur des tâches qui n’ont rien à voir avec l’analyse.
C’était un projet qu’on avait en tête depuis longtemps, sans jamais avoir le temps de s’y mettre. L’IA a changé l’équation : ce qui aurait pris des mois de développement classique est devenu faisable en side project.
Trois mois plus tard, on a des résultats qu’aucun benchmark ou keynote ne nous avait laissé imaginer.
On partage également cette expérimentation sur LinkedIn, au fil des évolutions. Pour suivre la série en temps réel, rendez-vous sur le profil de Matthieu (CTO & co-fondateur d’Hones).
Cet article condense les premiers épisodes. Voici ce qu'on a appris en chemin.
Le vrai défi : 80% de cadrage métier, 20% de technique
Au démarrage, on pensait que le challenge serait technique. Choisir le bon framework, configurer les agents, gérer les prompts. En réalité, la partie technique s’est révélée être la plus simple.
Le vrai travail, celui qui fait la différence entre un bot qui génère du texte et un outil qui apporte vraiment de la valeur, c’est de découper son métier en étapes suffisamment claires pour qu’un système puisse y contribuer.
Comprendre ce qui a de la valeur, ce qui n’en a pas, ce qu’on garde, ce qu’on délègue. Identifier les moments où l’IA peut aider et ceux où elle ne fait que compliquer. Définir les critères de qualité qui permettent de valider qu’un output est bon ou non.
Depuis qu’on travaille sur ce projet, on passe moins de temps à coder et plus de temps à se poser les bonnes questions sur notre propre métier. C’est probablement le gain le plus inattendu.
L’exemple de l’interface : comment bien briefer fait toute la différence
On a conçu l’interface complète de notre outil avec Claude. Un prototype React cliquable, hébergeable, testable. En deux jours. Sans designer.
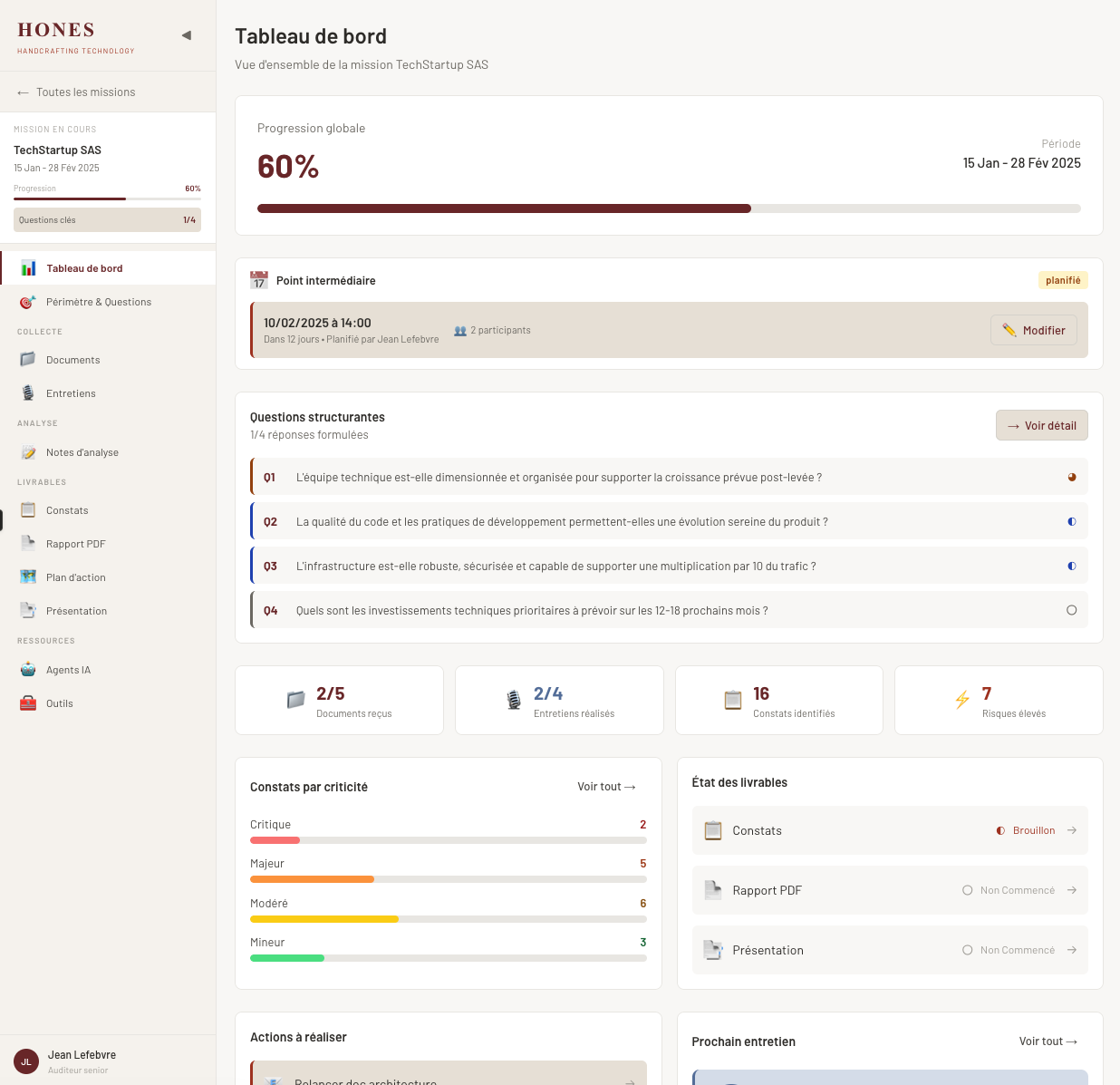
Au départ, on voulait juste que Claude nous aide à prompter Figma. En interagissant avec lui, on s’est rendu compte qu’il pouvait générer directement le prototype. On a sauté l’étape maquette.
Mais on ne lui a pas dit “fais-moi une interface”. On a structuré l’approche par étapes.
D’abord, générer des règles UX spécifiques à notre contexte. Résultat : un fichier Markdown qui devient le cadre de conception.
Ensuite, briefer un agent avec un contexte complet : ce qu’on fait chez Hones, qui utilise l’outil, pourquoi, des exemples de nos livrables actuels, notre brand book. Briefer l’IA comme on briefe un humain qui débarque sur le projet.
Puis itérer par couches. Structure globale d’abord (menu, navigation), puis descente dans le détail de chaque page. Quand on avait une idée précise, on la donnait. Sinon, on laissait Claude brainstormer à partir des objectifs.
Et superviser constamment. Vérifier que les règles métier sont respectées, que les parcours sont cohérents. Claude propose parfois des choses qui n’ont aucun sens d’un point de vue produit. Sans bases en conception, impossible de repérer ce qui cloche ou d’orienter efficacement.


Le constat est clair : si vous ne savez pas cadrer votre métier, l’IA ne le fera pas pour vous. Elle amplifie ce qui existe déjà. Un brief flou donnera un résultat flou. Une vision claire donnera un produit utilisable.
Trois pièges qu’on a rencontrés : tout mettre dans une seule conversation (ça finit par saturer), ne pas donner d’exemples concrets (l’IA a besoin de voir vos livrables réels), et ne pas itérer brique par brique (demander l’application complète d’un coup fait perdre plus de temps qu’on n’en gagne).
Trois pivots, trois leçons
Cette compréhension du cadrage métier, on l’a acquise progressivement. Mais pour y arriver, on a d’abord dû passer par une autre phase d’apprentissage : comprendre quels outils pouvaient vraiment tenir la route.
On avait fait nos devoirs en amont. Un benchmark des orchestrateurs, une matrice de critères, un choix rationnel. Mais on a quand même fini par changer trois fois de stack en trois mois. Pas par plaisir de repartir de zéro, mais parce que chaque changement répondait à un blocage concret qu’on découvrait en avançant.
Phase 1 : N8n, quand le POC ne suffit plus
On voulait aller vite. Un outil low-code semblait être le bon compromis : configuration rapide, pas besoin de coder, on branche l’IA et c’est parti.
Le POC a fonctionné. On a validé qu’on pouvait dialoguer avec un agent, générer des constats d’audit, formatter en Excel. Techniquement, ça marchait.
Mais dès qu’on a voulu scaler, les limites sont apparues. Impossible de versionner correctement. Le déploiement nécessitait une installation locale sur chaque machine. Pas d’observabilité pour suivre les coûts et les requêtes.
Le POC tournait. Mais impossible à industrialiser.
Le problème était simple : on avait validé une hypothèse technique, pas construit un produit. Les outils low-code sont parfaits pour cette première étape, mais ils montrent leurs limites dès qu’on veut passer à l’échelle. Versioning, déploiement, observabilité : ces sujets paraissent secondaires au début, ils deviennent bloquants très vite.
Phase 2 : LangChain, mieux structuré mais encore lent
Face à ces blocages, on a repris de zéro. Cette fois, objectif clair : versioning propre, déploiement simple, observabilité complète.
On a choisi LangChain parce qu’il était le plus éprouvé. Tout était autocontenu dans un projet GitHub. Chacun pouvait cloner et bosser dessus sans dépendre d’une config externe.
Ça fonctionnait mieux. Mais on était encore sur un mode classique : on écrivait du code, on gérait des agents, on configurait. On gagnait en scalabilité, mais on perdait toujours du temps sur l’exécution.
On avait résolu les problèmes d’infrastructure, mais pas changé fondamentalement le tempo. Choisir un framework éprouvé plutôt que le dernier outil à la mode fait gagner du temps, c’est vrai. Mais avoir une meilleure structure ne suffit pas si on reste dans un mode de développement classique.
Phase 3 : BMAD, le changement de paradigme
C’est à ce moment-là, alors qu’on cherchait encore comment accélérer, qu’on a découvert BMAD, un framework de spec driven development. Par hasard. Un message sur un Discord d’anciens collègues. On a testé par curiosité, sans grande attente.
Et là, tout a basculé.
Avec BMAD, on ne code plus comme avant. On manage une équipe virtuelle : PM, dev, UX, test. On découpe des tâches, on brief, on itère. Exactement comme avec une vraie équipe. Sauf que c’est beaucoup plus rapide.
Ça ne fait pas de magie pour autant. Quand le brief est flou, le résultat l’est aussi. On gère les mêmes problèmes qu’avec une équipe classique : des specs à clarifier, des bugs à corriger, des arbitrages à faire. La différence, c’est que tout va trois à quatre fois plus vite.
La vraie découverte : l’IA ne remplace pas la compétence, elle la démultiplie.
Le learning global : le terrain bat toujours la théorie
En regardant ce parcours avec du recul, une chose est claire : N8n semblait parfait sur le papier. Sur le terrain, ça ne tenait pas. BIMAD, l’outil qui a tout changé pour nous, on ne l’avait même pas dans notre benchmark initial. On l’a découvert par sérendipité.
Le pivot n’est pas un échec, c’est la méthode. Tester vite, voir ce qui coince, ajuster. C’est ce qui fait la différence au vu de la vitesse à laquelle l’IA évolue aujourd’hui.
Les chiffres qui ont tout changé
Ces pivots successifs nous ont menés quelque part qu’on n’imaginait pas au départ. Il y a deux mois, on pensait que l’IA ne pouvait pas faire de vrais produits. Aujourd’hui, on en livre un par semaine.
Un projet récent pour un de nos clients a confirmé ce basculement. Une plateforme de gestion pour suivre des métriques métier en temps réel. Dashboard, backend, base de données, mise en production. Le type de projet qui mobilise habituellement plusieurs profils sur plusieurs mois.
Timeline classique : trois mois. Équipe classique : PM, designer, deux développeurs. Budget : plusieurs dizaines de milliers d’euros.
Résultat obtenu : sept jours, une personne, un dixième du coût.
Les chiffres :
Temps : divisé par 12
Équipe : divisée par 3
Budget : divisé par 10
La qualité est restée équivalente parce que la personne qui pilotait savait cadrer et arbitrer. L’IA a démultiplié sa capacité d’exécution sans remplacer son expertise.
Sur les projets internes, même constat. En trois semaines, plus d’outils produits qu’en deux ans. Sans impact sur les missions en cours. Sans recrutement.
Ces projets ne dorment plus dans un backlog en attendant du temps ou une embauche. Ils avancent entre deux réunions. La contrainte “on n’a pas les ressources” a cessé d’être un blocage automatique.
Ce qui était structurellement impossible devient faisable.
Les questions à se poser maintenant
Ces chiffres qui étaient encore jusqu’ici impensables, viennent de changer l’équation économique du développement. Pas juste pour nous. Pour toute organisation tech.
Un projet qui représentait un investissement lourd devient accessible. Un délai qui imposait des arbitrages difficiles devient gérable. Une roadmap qu’on devait étaler se compresse.
Votre backlog est-il basé sur d’anciennes contraintes ?
Regardez les projets que vous avez mis de côté ces douze derniers mois. Combien d’entre eux sont en pause avec cette justification : “on n’a pas les ressources” ?
Ce calcul était valide il y a six mois. Il ne l’est probablement plus aujourd’hui. Quand une personne qui sait cadrer peut livrer ce qui nécessitait une équipe complète, la contrainte change de nature.
Ça ne signifie pas qu’il faut réduire les équipes. Ça signifie que ce qui était structurellement impossible devient faisable. Les projets qu’on ne lançait pas par manque de temps ou de budget méritent d’être réévalués.
Combien de temps avant que vos concurrents aient ces chiffres ?
Pendant que vous attendez que l’IA devienne plus mature, d’autres organisations testent. Elles accumulent des résultats similaires. Elles réallouent leurs ressources en conséquence.
L’écart se mesure déjà. Diviser ses coûts de développement par 3 à 10. Ou multiplier par 10 ce qu’on livre avec le même budget. Tester une hypothèse produit en une semaine au lieu de trois mois. Ce ne sont plus des projections, ce sont des faits mesurés.
Ceux qui attendent que l’IA “s’améliore” ne voient pas que d’autres ont déjà changé leur façon de travailler. L’écart ne va pas se résorber. Il va s’accentuer.
Par où commencer ?
La réponse est plus simple qu’elle n’y paraît. Le vrai défi n’est pas technique. Il est méthodologique.
Il faut savoir découper son métier en étapes suffisamment claires pour qu’un système puisse y contribuer. Identifier ce qui a de la valeur et ce qui n’en a pas. Définir ce qu’on garde et ce qu’on délègue. Établir les critères qui permettent de valider qu’un résultat est acceptable.
Si ce cadrage n’existe pas, l’IA ne le créera pas. Elle amplifie ce qui existe déjà. Un brief vague produira un résultat vague. Une vision structurée produira quelque chose d’utilisable.
Le coût d’attendre dépasse maintenant le coût de tester. Si vous pilotez encore avec les hypothèses d’il y a six mois, vous prenez probablement des décisions sur des bases périmées.
L’expérimentation continue
On ne s’arrête pas là. Cette expérimentation continue. On teste de nouveaux outils, on mesure de nouveaux cas d’usage, on accumule des learnings.
Dans les prochains mois, on va documenter d’autres aspects : comment on gère les erreurs d’agents IA en production, comment on mesure la qualité des outputs, comment on forme les équipes à piloter ces outils, les limites qu’on a rencontrées et comment on les contourne.
Ce qu’on a condensé ici, ce sont les trois premiers mois. Les bases. Ce qui permet de démarrer et d’éviter certains écueils.
Pour suivre la série en temps réel sur Linkedin et voir comment ça évolue, c’est ici que ça se passe.